
새로운 세계 상위 500대 슈퍼컴퓨터 랭킹이 인공지능(AI)과 데이터 애널리틱스로 확장되고 엔비디아 기술로 가속화된 현대 과학 컴퓨팅의 현황을 보여주고 있는데요. 이 랭킹에 따르면 세계 10대 슈퍼컴퓨터 중 8대가 엔비디아 GPU나 멜라녹스의 인피니밴드(InfiniBand) 네트워킹을 활용하고 있다고 합니다. 여기에는 미국, 유럽, 중국에 걸친 가장 강력한 슈퍼컴퓨터들도 포함됩니다.
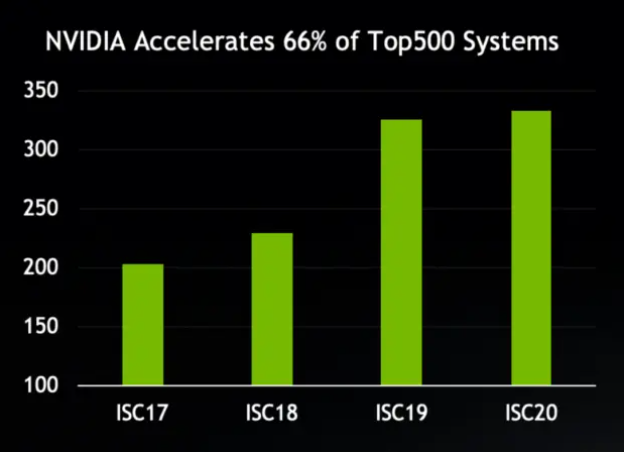
멜라녹스 인수 이후 엔비디아는 전세계 상위 500대 슈퍼컴퓨터 중 약 3분의 2에 해당하는 333개를 지원하고 있습니다. 또한, 인피니밴드 시스템을 채택한 슈퍼컴퓨터 중 약 74%가 멜라녹스 HDR 200G 인피니밴드를 도입했습니다. HDR 인피니밴드를 사용하는 전세계 상위 500대 슈퍼컴퓨터의 수는 2019년 11월 이후 거의 두 배가 증가했습니다.
엔비디아 멜라녹스 인피니밴드와 이더넷 네트워크는 전세계 상위 500대 슈퍼컴퓨터의 61%에 달하는 305대의 시스템을 연결하는데, 여기에는 인피니밴드 시스템을 채택한 141대의 슈퍼컴퓨터와 이더넷 네트워크를 사용하는 164대의 시스템이 해당됩니다.
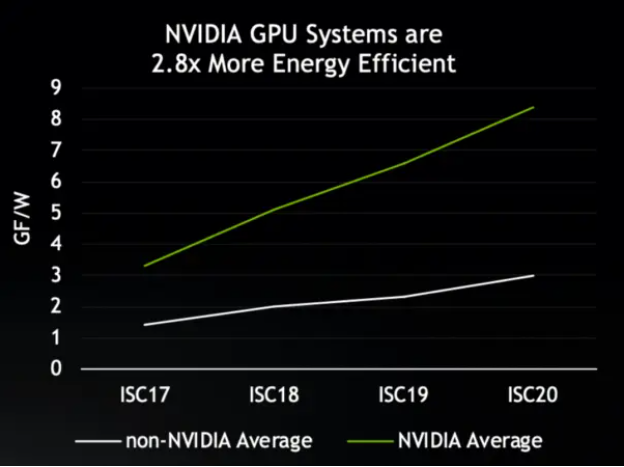
엔비디아 GPU를 사용하는 시스템은 에너지 효율 측면에서 우위를 차지하고 있습니다. 평균적으로 기가플롭/와트 단위로 측정 시 엔비디아 GPU를 장착하지 않은 시스템 대비 2.8배 높은 전력효율을 구현합니다. 이는 엔비디아 GPU가 현재 전세계 상위 500대 슈퍼컴퓨터 목록에서 상위 25대 슈퍼컴퓨터 중 무려 20대에 사용되는 이유이기도 합니다.
최근 엔비디아 내부 연구 클러스터에 추가된 셀린(Selene)은 높은 전력 효율을 보여주는 좋은 사례입니다. 해당 시스템은 그린 500(Green500) 리스트에서 2위를 차지하고, 린팩(Linpack) 벤치마크에서 27.5 페타플롭의 성능을 달성하며 전세계 상위 500대 슈퍼컴퓨터 중 7위를 기록했습니다. 셀린은 전세계 상위 500대 슈퍼컴퓨터 중 20기가플롭/와트의 장벽을 깬 유일한 상위 100대 시스템입니다. 이 시스템은 또한 엔비디아 GPU를 사용하는 이탈리아의 거대 에너지 기업 Eni S.p.A의 시스템에 이어 세계에서 두 번째로 강력한 산업용 슈퍼컴퓨터입니다.
에너지 사용 측면에서 보자면, 셀린은 엔비디아 GPU를 사용하지 않는 시스템과 비교해 6.8배 효율적입니다. 셀린의 성능과 에너지 효율은 엔비디아 A100 GPU의 3세대 텐서 코어가 시뮬레이션을 위한 기존 64 비트 연산속도를 높이고 AI 정밀 작업을 낮춘 덕분입니다. 셀린은 구축까지 4주가 채 걸리지 않은 시스템으로, 엔지니어들은 엔비디아의 모듈식 레퍼런스 아키텍처인 엔비디아 DGX 슈퍼POD를 사용해 셀린을 빠르게 조립할 수 있었습니다. 엔비디아 DGX 슈퍼POD는 현대적인 데이터센터를 위한 강력하면서도 유연한 빌딩블록인 엔비디아 DGX A100 시스템을 기반으로 합니다. DGX A100은 엔비디아 멜라녹스 HDR 인피니밴드 네트워킹을 통해 6U 서버에 8개의 A100 GPU를 패키징하는 유연한 시스템으로, 고성능컴퓨팅(HPC), 데이터 애널리스틱, AI 훈련 및 추론을 가속화하도록 설계됐다.
슈퍼POD로 시스템 확장
레퍼런스 설계를 통해 어느 조직이든 빠르게 세계적 수준의 컴퓨팅 클러스터를 구축할 수 있습니다. 고성능 엔비디아 멜라녹스 인피니밴드 스위치는 20대의 DGX A100 시스템을 마치 레고처럼 연결합니다.
4명의 운영자는 1시간 이내에 20개의 DGX A100 클러스터를 랙에 장착하여 전세계 상위 500대 슈퍼컴퓨터 목록에 포함될 정도로 강력한 2페타플롭의 성능을 내는 시스템을 만들 수 있습니다. 이러한 시스템은 표준 데이터센터의 전력 및 열 성능 내에서 원활하게 작동하도록 설계됐습니다.
엔지니어들은 엔비디아 멜라녹스 인피니밴드 스위치를 통해 20개 시스템 유닛 중 14개를 연결하여 셀린을 구축했습니다. 또한, 여기에는 아래의 항목들이 포함됩니다.
- 280개의 DGX A100 시스템
- 2,240개의 엔비디아 A100 GPU
- 494개의 엔비디아 멜라녹스 퀀텀(Quantum) 200G 인피니밴드 스위치
- 56 TB/s의 네트워크 패브릭
- 7PB의 고성능 올플래시 스토리지
셀린의 가장 중요한 특징 중 하나는 1 엑사플롭스(exaflops) 이상의 AI 성능을 낼 수 있다는 점인데요. 더불어, 셀린은 단 16대의 DGX A100 시스템을 사용해 TPCx-BB라 불리는 핵심 데이터 분석 벤치마크에서 다른 시스템보다 약 20배 뛰어난 성능을 내며 새로운 기록을 세웠습니다.
아직 전세계 상위 500대 슈퍼컴퓨터에 포함되지 않은 6개의 시스템이 엔비디아 A100 GPU를 통해 구축되고 있습니다. 그 중 하나는 아르곤 국립 연구소(Argonne National Laboratory)에 있는데 해당 연구소 연구원들은 24개의 엔비디아 DGX A100 시스템으로 구성된 클러스터를 활용해 코로나19 치료법을 찾기 위한 수십억 개의 약물 스캔 작업을 수행하고 있습니다. 또한, 미 국가 에너지 연구 과학 컴퓨팅 센터(NERSC)는 6,200개의 A100 GPU가 장착된 엑사스케일급 시스템 펄머터(Perlmutter)를 대상으로 하는 여러 프로젝트에 AI를 활용하고 있습니다. 이 밖에도, 뮌헨의 연구원들은 서밋(Summit) 슈퍼컴퓨터에 장착된 6,000개의 GPU에서 자연어 모델을 훈련시켜 코로나바이러스 단백질 분석 속도를 높이고 있습니다.
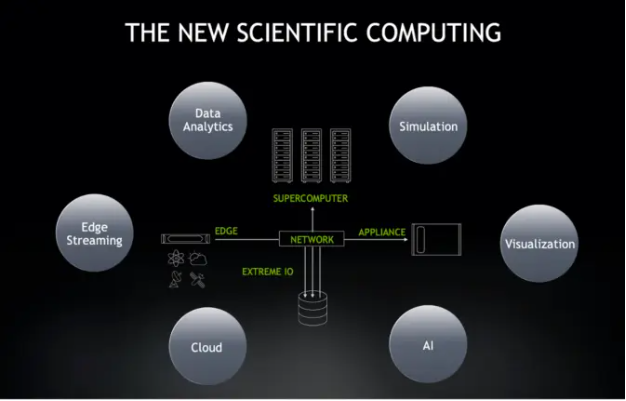
과학자들이 딥 러닝과 애널리틱스를 활용해 연구를 가속화하면서, 클라우드 서비스에 접근하고 네트워크 엣지 상의 원격 기기에서 데이터를 스트리밍 하고 있습니다. 이를 지원하기 위해, 엔비디아는 다음의 네 가지 과학 컴퓨팅 영역에 집중하고 있습니다.
- 시뮬레이션: 코로나19에 대응하기 위해 미 오크리지국립연구소 연구원들은 서밋 슈퍼컴퓨터 GPU에서 오토독(AutoDock)을 실행하면서 24시간 동안 20억개가 넘는 화합물을 시뮬레이션 하고 있습니다.
- AI 및 데이터 분석: 스파크(Spark) 3.0을 위한 GPU 가속은 중요하면서도 많은 시간이 요구되는 머신러닝 속도를 한층 개선합니다.
- 엣지 스트리밍: CERN(European Research for Nuclear Research)은 최근 엔비디아 GPU를 사용하여 세계 최대의 에너지 입자 충돌기인 LHC(Large Hadron Collider)내에서 입자 충돌 이벤트로 생성된 대량의 데이터를 500배 줄일 수 있다고 발표했습니다.
- 가상화: 엔비디아의 IndeX와 매그넘 IO(Magnum IO) 소프트웨어는 화성 착륙선 시각화를 돕습니다.
점점 더 많은 기업들은 물론 연구자들이 클라우드부터 네트워크 엣지까지 AI 및 애널리틱스의 가속화를 모색하면서 세계 최대 클라우드 서비스 제공업체들과 OEM 파트너들이 엔비디아 GPU 채택을 확대하고 있습니다. 이번에 발표된 전세계 500대 슈퍼컴퓨터 리스트는 AI와 HPC를 민주화하려는 엔비디아의 노력이 반영된 것이라 할 수 있습니다.