
NVIDIA Research 팀은 이미지, 비디오 및 3D 환경을 생성하고 해석하는 새로운 기술을 개발하며 빠르게 발전하고 있는 비주얼 생성형 AI 분야의 선두에 서 있습니다.
이 중 50개 이상의 프로젝트가 6월 17일부터 21일까지 시애틀에서 열리는 CVPR(Computer Vision and Pattern Recognition) 컨퍼런스에서 공개되었습니다. 이 중 확산 모델(Diffusion models)의 훈련 역학에 관한 논문과 자율 주행 자동차를 위한 고해상도 지도에 관한 논문까지 이렇게 두 편이 CVPR의 최우수 논문상 최종 후보에 올랐습니다.
또한, NVIDIA는 포괄적인 자율 주행 모델을 위한 생성형 AI의 활용을 입증하는 중요한 이정표인 CVPR Autonomous Grand Challenge의 엔드 투 엔드 대규모 주행 트랙에서 우승했습니다. 전 세계 450개 이상의 출품작을 제치고 우승한 이 작품은 CVPR의 혁신상도 수상했습니다.
CVPR에서 NVIDIA는 특정 물체나 캐릭터를 묘사하도록 쉽게 커스터마이징할 수 있는 텍스트-이미지 모델, 물체 자세 추정을 위한 새로운 모델, NeRF(Neural radiance fields) 편집 기술, 밈을 이해할 수 있는 시각 언어 모델 등을 연구하고 있습니다. 추가적인 논문에서는 오토모티브,헬스케어, 로보틱스 등 산업 분야별 혁신을 소개합니다.
이를 종합하면, 크리에이터가 자신의 예술적 비전을 보다 빠르게 실현하고, 제조업을 위한 오토노머스 머신의 학습을 가속화하며, 방사선 보고서 처리를 도와 헬스케어 전문가를 지원할 수 있는 강력한 AI 모델을 소개합니다.
“인공 지능, 특히 생성형 AI는 중추적인 기술 발전을 상징합니다.”라고 NVIDIA의 학습 및 인식 연구 담당 부사장인 Jan Kautz는 말합니다. “CVPR에서 NVIDIA Research팀은 전문 크리에이터의 역량을 강화할 수 있는 강력한 이미지 생성 모델부터 차세대 자율 주행 자동차를 구현하는 데 도움이 될 수 있는 자율 주행 소프트웨어까지, NVIDIA가 어떻게 가능성의 한계를 넓혀가고 있는지 공유할 것입니다.”
또한, NVIDIA는 CVPR에서 모든 종류의 완전 오토노머스 머신 개발을 가속화하기 위해 물리적으로 정확한 센서 시뮬레이션을 지원하는 마이크로서비스 세트인 NVIDIA Omniverse Cloud Sensor RTX를 발표했습니다.
파인 튜닝은 잊어라: 맞춤 이미지 생성을 간소화시키는 JeDi
텍스트 프롬프트를 기반으로 이미지를 생성하는 가장 인기 있는 방법인 확산 모델을 활용하는 크리에이터는 종종 특정 캐릭터나 사물을 염두에 두고 있습니다. 예를 들어, 애니메이션 마우스에 대한 스토리보드를 개발하거나 특정 장난감의 광고 캠페인을 브레인스토밍할 수 있습니다.
이전 연구를 통해 이러한 크리에이터는 사용자가 맞춤 데이터 세트에 대해 모델을 훈련시키는 파인 튜닝을 통해 특정 주제에 초점을 맞추도록 확산 모델의 결과를 개인화할 수 있었지만, 이 과정은 시간이 많이 걸리고 일반 사용자가 접근하기 어려울 수 있습니다.
존스 홉킨스 대학교, 시카고 도요타 기술 연구소, NVIDIA의 연구진이 발표한 논문인 JeDi는 사용자가 레퍼런스 이미지를 사용하여 몇 초 내에 확산 모델의 출력을 쉽게 개인화할 수 있는 새로운 기술을 선보입니다. 연구팀은 이 모델이 기존의 파인 튜닝 기반 또는 파인 튜닝이 필요 없는 방법을 훨씬 능가하는 최첨단 품질을 달성한다는 사실을 발견했습니다.
또한 JeDi는 검색 증강 생성(RAG)과 결합하여 브랜드의 제품 카탈로그와 같은 데이터베이스에 특화된 시각적 이미지를 생성할 수도 있습니다.
새로운 파운데이션 모델로 완벽한 포즈
CVPR에서 NVIDIA Research는 파인 튜닝 없이도 추론 중에 새로운 물체에 즉시 적용할 수 있는 물체 자세 추정 및 추적을 위한 파운데이션 모델인 FoundationPose도 발표했습니다.
물체 포즈 추정 분야에서 널리 사용되는 벤치마크에서 새로운 기록을 세운 이 모델은 작은 참조 이미지 세트 또는 물체의 3D 표현을 사용하여 물체의 모양을 파악합니다. 그런 다음 열악한 조명 조건이나 시각적 장애물이 있는 복잡한 장면에서도 해당 물체가 동영상 전체에서 3D로 어떻게 움직이고 회전하는지 식별하고 추적할 수 있습니다.
FoundationPose는 자율 로봇이 상호작용하는 물체를 식별하고 추적하는 데 도움이 되는 산업용 애플리케이션에 사용될 수 있습니다. 또한 AI 모델을 사용하여 라이브 장면에 시각적 효과를 오버레이하는 증강 현실 애플리케이션에도 사용할 수 있습니다.
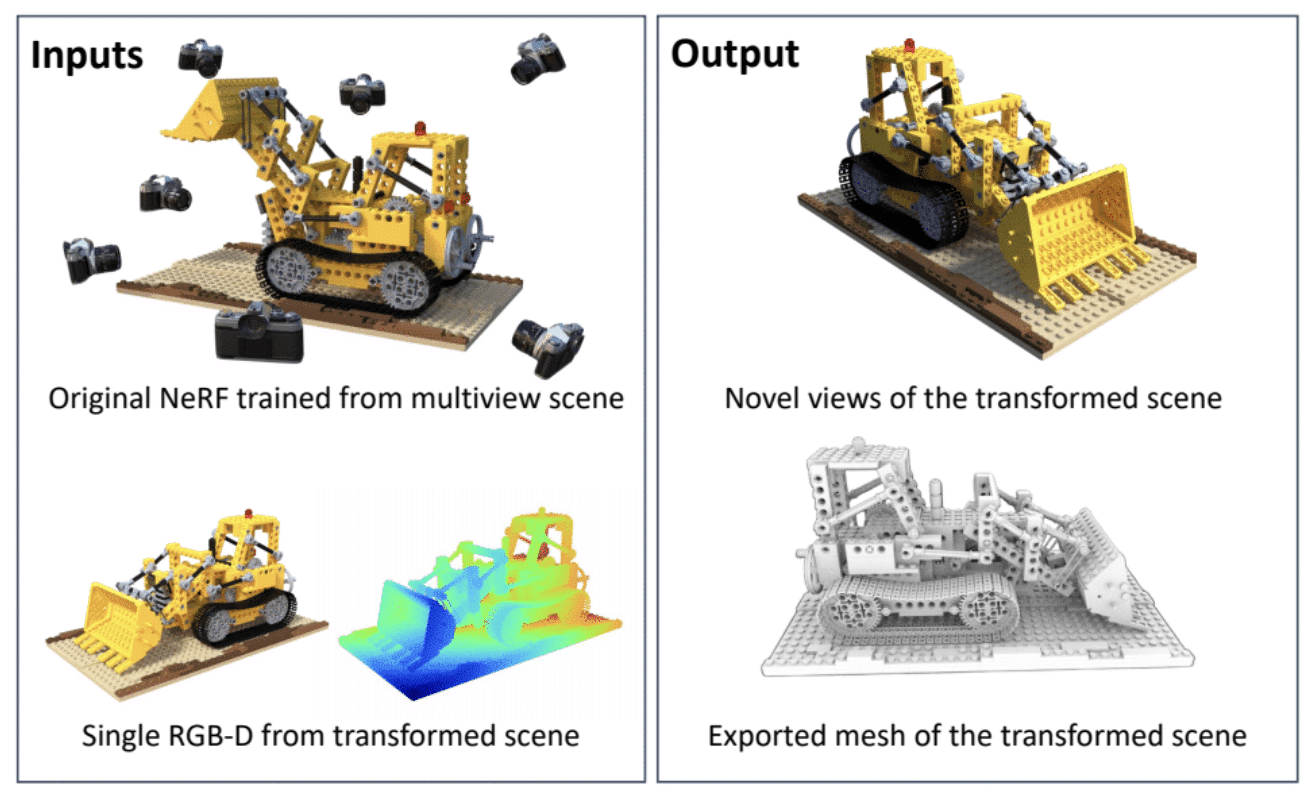
단일 스냅샷으로 3D 장면을 변환하는 NeRFDeformer
NeRF는 환경의 여러 위치에서 촬영한 일련의 2D 이미지를 기반으로 3D 장면을 렌더링할 수 있는 AI 모델입니다. 로보틱스 같은 분야에서는 복잡한 방이나 건설 현장과 같은 복잡한 실제 장면의 몰입형 3D 렌더링을 생성하는 데 NeRF를 사용할 수 있습니다. 그러나 장면을 변경하려면 개발자가 장면의 변형 방식을 수동으로 정의하거나 NeRF를 완전히 다시 제작해야 합니다.
일리노이대학교 어바나-샴페인 캠퍼스(University of Illinois Urbana-Champaign)와 NVIDIA의 연구원들은 NeRFDeformer를 통해 이 과정을 간소화했습니다. CVPR에서 발표된 이 방법은 일반 사진과 장면의 각 오브젝트가 카메라에서 얼마나 멀리 떨어져 있는지 캡처하는 뎁스 맵(Depth map)의 조합인 단일 RGB-D 이미지를 사용하여 기존 NeRF를 성공적으로 변환할 수 있습니다.
VILA 시각 언어 모델을 통한 그림 이해
NVIDIA와 매사추세츠 공과대학의 CVPR 연구 협력은 비디오, 이미지 및 텍스트를 처리할 수 있는 생성형 AI 모델인 비전 언어 모델의 최첨단 기술을 발전시키고 있습니다.
이 그룹은 AI 모델이 이미지에 대한 질문에 얼마나 잘 대답하는지 테스트하는 주요 벤치마크에서 이전 뉴럴 네트워크보다 뛰어난 성능을 보이는 오픈 소스 시각 언어 모델 제품군인 VILA를 개발했습니다. VILA의 고유한 사전 학습 프로세스를 통해 향상된 세계 지식, 강력한 맥락 학습, 여러 이미지에 대한 추론 능력 등 새로운 모델 기능을 구현할 수 있었습니다.

VILA 모델 제품군은 데이터센터, 워크스테이션, 심지어 엣지 디바이스의 NVIDIA GPU에 배포할 수 있는 NVIDIA TensorRT-LLM 오픈 소스 라이브러리를 사용하여 추론에 최적화할 수 있습니다.
VILA에 대한 자세한 내용은 NVIDIA 기술 블로그와 GitHub에서 확인하세요.
자율 주행, 스마트 시티 연구를 촉진하는 생성형 AI
NVIDIA가 작성한 12개의 CVPR 논문은 자율 주행 자동차 연구에 초점을 맞추고 있습니다. 기타 AV 관련 주요 내용은 다음과 같습니다:
- 이 데모에서는 CVPR Autonomous Grand Challenge에서 우승한 NVIDIA의 AV 응용 연구를 소개하였습니다.
- 6월 17일에 열리는 자율 주행 워크숍에서 NVIDIA의 AI 연구 담당 부사장인 Sanja Fidler가 비전 언어 모델에 대해 발표할 예정입니다.
- 토론토 대학교와 NVIDIA의 연구진이 작성한 논문인 ‘Producing and Leveraging Online Map Uncertainty in Trajectory Prediction‘이 CVPR의 최우수 논문상 최종 후보 24편 중 하나로 선정되었습니다.
또한 CVPR에서 NVIDIA는 AI 시티 챌린지에 역대 최대 규모의 실내 합성 데이터세트를 제공하여 연구자와 개발자가 스마트 시티와 산업 자동화를 위한 솔루션 개발을 발전시킬 수 있도록 지원했습니다. 챌린지의 데이터 세트는 개발자가 OpenUSD 기반 애플리케이션과 워크플로우를 구축할 수 있도록 지원하는 API, SDK 및 서비스 플랫폼인 NVIDIA Omniverse를 사용하여 생성되었습니다.
전 세계 수백 명의 과학자와 엔지니어가 AI, 컴퓨터 그래픽, 컴퓨터 비전, 자율 주행 자동차, 로보틱스 등의 주제에 집중하는 팀을 보유하고 있는 NVIDIA Research이 CVPR에서 발표한 내용을 확인하세요.