
인공 지능과 머신 러닝, 딥 러닝의 차이점을 알아보자
세기의 바둑대전에서 구글 딥마인드의 인공지능 ‘알파고(AlphaGo)’ 프로그램이 한국의 이세돌 9단을 꺾었을 때, 알파고의 승리 배경을 논할 때 인공 지능과 머신 러닝, 딥 러닝의 정확한 개념에 대해 혼란을 느끼시는 분들이 많으셨을텐데요^^
오늘은 이러한 세가지 개념에 대해서 명쾌하게 설명해 드리겠습니다. 이러한 세 가지 개념의 관계를 가장 쉽게 파악하는 방법은 세 개의 동심원을 상상하는 것입니다. 인공 지능이 가장 큰 원이고, 그 다음이 머신 러닝이며, 현재의 인공지능 붐을 주도하는 딥 러닝이 가장 작은 원이라 할 수 있죠.
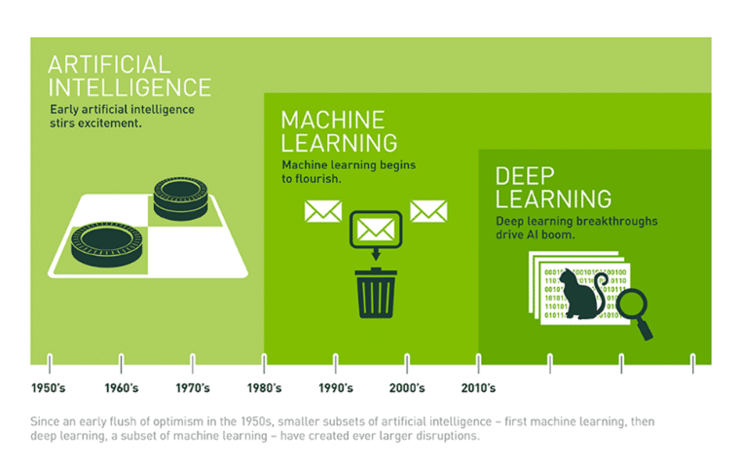
인공지능 기술의 탄생 및 성장
인공 지능이라는 개념은 1956년 미국 다트머스 대학에 있던 존 매카시 교수가 개최한 다트머스 회의에서 처음 등장했으며, 최근 몇 년 사이 폭발적으로 성장하고 있는 중이랍니다. 특히 2015년 이후 신속하고 강력한 병렬 처리 성능을 제공하는 GPU의 도입으로 더욱 가속화되고 있죠. 갈수록 폭발적으로 늘어나고 있는 저장 용량과 이미지, 텍스트, 매핑 데이터 등 모든 영역의 데이터가 범람하게 된 ‘빅데이터’ 시대의 도래도 이러한 성장세에 큰 영향을 미쳤습니다.
인공 지능: 인간의 지능을 기계로 구현하다

1956년 당시 인공 지능의 선구자들이 꿈꾼 것은 최종적으로 인간의 지능과 유사한 특성을 가진 복잡한 컴퓨터를 제작하는 것이었죠. 이렇듯 인간의 감각, 사고력을 지닌 채 인간처럼 생각하는 인공 지능을 ‘일반 AI(General AI)’라고 하지만, 현재의 기술 발전 수준에서 만들 수 있는 인공지능은 ‘좁은 AI(Narrow AI)’의 개념에 포함됩니다. 좁은 AI는 소셜 미디어의 이미지 분류 서비스나 얼굴 인식 기능 등과 같이 특정 작업을 인간 이상의 능력으로 해낼 수 있는 것이 특징이죠.
머신 러닝: 인공 지능을 구현하는 구체적 접근 방식
머신 러닝은 메일함의 스팸을 자동으로 걸러주는 역할을 합니다.
한편, 머신 러닝은 기본적으로 알고리즘을 이용해 데이터를 분석하고, 분석을 통해 학습하며, 학습한 내용을 기반으로 판단이나 예측을 합니다. 따라서 궁극적으로는 의사 결정 기준에 대한 구체적인 지침을 소프트웨어에 직접 코딩해 넣는 것이 아닌, 대량의 데이터와 알고리즘을 통해 컴퓨터 그 자체를 ‘학습’시켜 작업 수행 방법을 익히는 것을 목표로 한답니다.
머신 러닝은 초기 인공 지능 연구자들이 직접 제창한 개념에서 나온 것이며, 알고리즘 방식에는 의사 결정 트리 학습, 귀납 논리 프로그래밍, 클러스터링, 강화 학습, 베이지안(Bayesian) 네트워크 등이 포함됩니다. 그러나 이 중 어느 것도 최종 목표라 할 수 있는 일반 AI를 달성하진 못했으며, 초기의 머신 러닝 접근 방식으로는 좁은 AI조차 완성하기 어려운 경우도 많았던 것이 사실이죠.
현재 머신 러닝은 컴퓨터 비전 등의 분야에서 큰 성과를 이뤄내고 있으나, 구체적인 지침이 아니더라도 인공 지능을 구현하는 과정 전반에 일정량의 코딩 작업이 수반된다는 한계점에 봉착하기도 했는데요. 가령 머신 러닝 시스템을 기반으로 정지 표지판의 이미지를 인식할 경우, 개발자는 물체의 시작과 끝 부분을 프로그램으로 식별하는 경계 감지 필터, 물체의 면을 확인하는 형상 감지, ‘S-T-O-P’와 같은 문자를 인식하는 분류기 등을 직접 코딩으로 제작해야 합니다. 이처럼 머신 러닝은 ‘코딩’된 분류기로부터 이미지를 인식하고, 알고리즘을 통해 정지 표지판을 ‘학습’하는 방식으로 작동된답니다.
머신 러닝의 이미지 인식률은 상용화하기에 충분한 성능을 구현하지만, 안개가 끼거나 나무에 가려서 표지판이 잘 보이지 않는 특정 상황에서는 이미지 인식률이 떨어지기도 한답니다. 최근까지 컴퓨터 비전과 이미지 인식이 인간의 수준으로 올라오지 못한 이유는 이 같은 인식률 문제와 잦은 오류 때문이죠.
딥 러닝: 완전한 머신 러닝을 실현하는 기술

초기 머신 러닝 연구자들이 만들어 낸 또 다른 알고리즘인 인공 신경망(artificial neural network)에 영감을 준 것은 인간의 뇌가 지닌 생물학적 특성, 특히 뉴런의 연결 구조였습니다. 그러나 물리적으로 근접한 어떤 뉴런이든 상호 연결이 가능한 뇌와는 달리, 인공 신경망은 레이어 연결 및 데이터 전파 방향이 일정합니다.
예를 들어, 이미지를 수많은 타일로 잘라 신경망의 첫 번째 레이어에 입력하면, 그 뉴런들은 데이터를 다음 레이어로 전달하는 과정을 마지막 레이어에서 최종 출력이 생성될 때까지 반복합니다. 그리고 각 뉴런에는 수행하는 작업을 기준으로 입력의 정확도를 나타내는 가중치가 할당되며, 그 후 가중치를 모두 합산해 최종 출력이 결정됩니다.
정지 표지판의 경우, 팔각형 모양, 붉은 색상, 표시 문자, 크기, 움직임 여부 등 그 이미지의 특성이 잘게 잘려 뉴런에서 ‘검사’되며, 신경망의 임무는 이것이 정지 표지판인지 여부를 식별하는 것입니다. 여기서는 충분한 데이터를 바탕으로 가중치에 따라 결과를 예측하는 ‘확률 벡터(probability vector)’가 활용되죠.
딥 러닝은 인공신경망에서 발전한 형태의 인공 지능으로, 뇌의 뉴런과 유사한 정보 입출력 계층을 활용해 데이터를 학습합니다. 그러나 기본적인 신경망조차 굉장한 양의 연산을 필요로 하는 탓에 딥 러닝의 상용화는 초기부터 난관에 부딪혔죠. 그럼에도 토론토대의 제프리 힌튼(Geoffrey Hinton) 교수 연구팀과 같은 일부 기관에서는 연구를 지속했고, 슈퍼컴퓨터를 기반으로 딥 러닝 개념을 증명하는 알고리즘을 병렬화하는데 성공했습니다. 그리고 병렬 연산에 최적화된 GPU의 등장은 신경망의 연산 속도를 획기적으로 가속하며 진정한 딥 러닝 기반 인공 지능의 등장을 불러왔죠.
신경망 네트워크는 ‘학습’ 과정에서 수많은 오답을 낼 가능성이 큽니다. 정지 표지판의 예로 돌아가서, 기상 상태, 밤낮의 변화에 관계 없이 항상 정답을 낼 수 있을 정도로 정밀하게 뉴런 입력의 가중치를 조정하려면 수백, 수천, 어쩌면 수백만 개의 이미지를 학습해야 할지도 모르죠. 이 정도 수준의 정확도에 이르러서야 신경망이 정지 표지판을 제대로 학습했다고 볼 수 있습니다.
2012년, 구글과 스탠퍼드대 앤드류 응(Andrew NG) 교수는 1만6,000개의 컴퓨터로 약 10억 개 이상의 신경망으로 이뤄진 ‘심층신경망(Deep Neural Network)’을 구현했습니다. 이를 통해 유튜브에서 이미지 1,000만 개를 뽑아 분석한 뒤, 컴퓨터가 사람과 고양이 사진을 분류하도록 하는데 성공했습니다. 컴퓨터가 영상에 나온 고양이의 형태와 생김새를 인식하고 판단하는 과정을 스스로 학습하게 한 것이죠.
딥 러닝으로 훈련된 시스템의 이미지 인식 능력은 이미 인간을 앞서고 있습니다. 이 밖에도 딥 러닝의 영역에는 혈액의 암세포, MRI 스캔에서의 종양 식별 능력 등이 포함됩니다. 구글의 알파고는 바둑의 기초를 배우고, 자신과 같은 AI를 상대로 반복적으로 대국을 벌이는 과정에서 그 신경망을 더욱 강화해 나갔습니다.
딥 러닝으로 밝은 미래를 꿈꾸는 인공 지능
딥 러닝의 등장으로 인해 머신 러닝의 실용성은 강화됐고, 인공 지능의 영역은 확장됐죠. 딥 러닝은 컴퓨터 시스템을 통해 지원 가능한 모든 방식으로 작업을 세분화합니다. 운전자 없는 자동차, 더 나은 예방 의학, 더 정확한 영화 추천 등 딥 러닝 기반의 기술들은 우리 일상에서 이미 사용되고 있거나, 실용화를 앞두고 있습니다. 딥 러닝은 공상과학에서 등장했던 일반 AI를 실현할 수 있는 잠재력을 지닌 인공 지능의 현재이자, 미래로 평가 받고 있답니다.