
온디바이스 AI 시대를 이끄는 오픈 모델은 이제 클라우드를 넘어 일상적인 디바이스까지 혁신을 확장하고 있습니다. 오픈 모델이 발전하면서 의미 있는 인사이트를 실제 행동으로 연결하는 실시간 로컬 컨텍스트 접근성이 핵심 요소로 부상하고 있는데요.
이러한 변화에 맞춰 설계된 구글(Google)의 최신 젬마 4(Gemma 4) 제품군은 다양한 디바이스에서 효율적인 로컬 실행을 지원하는 소형 고속 다기능 모델을 제공합니다.
NVIDIA와 구글은 젬마 4를 NVIDIA GPU에 최적화하기 위해 협력했습니다. 이를 통해 데이터센터 배치부터 NVIDIA RTX 기반 PC와 워크스테이션, 개인용 AI 슈퍼컴퓨터인 NVIDIA DGX Spark, NVIDIA Jetson Orin Nano 엣지 AI 모듈에 이르기까지 다양한 환경에서 효율적인 성능을 구현할 수 있죠.
젬마 4: NVIDIA GPU에 최적화된 콤팩트 모델
젬마 4 오픈 모델 제품군의 최신 라인업인 E2B, E4B, 26B, 31B 모델은 엣지 디바이스부터 고성능 GPU까지 효율적인 배포를 위해 설계됐습니다. 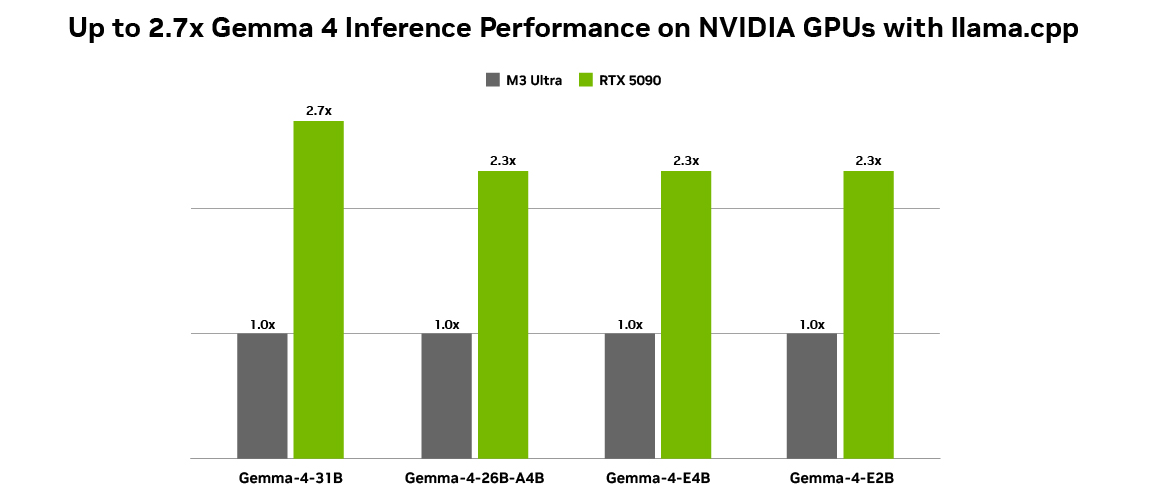
모든 구성은 NVIDIA GeForce RTX 5090과 맥 M3 울트라(Mac M3 Ultra) 데스크톱에서 Q4_K_M 양자화, BS = 1, ISL = 4096, OSL = 128 조건으로 측정됐습니다. 토큰 생성 처리량은 라마.cpp(llama.cpp) b7789에서 라마 벤치 도구를 활용해 산출됐습니다.
차세대 콤팩트 모델은 다음과 같은 다양한 작업을 지원합니다.
- 추론: 복잡한 문제 해결 작업에서 강력한 성능 제공
- 코딩: 개발자 워크플로우를 위한 코드 생성과 디버깅 지원
- 에이전트: 구조화된 도구 사용(함수 호출) 기본 지원
- 비전비디오·오디오 기능: 객체 인식, 자동 음성 인식, 문서·비디오 인텔리전스를 위한 다양한 멀티모달 상호작용 지원
- 인터리브드(Interleaved) 멀티모달 입력: 하나의 프롬프트에서 텍스트와 이미지를 자유롭게 혼합
- 다중 언어: 35개 이상 언어 기본 지원, 140개 이상 언어로 사전 훈련
E2B와 E4B 모델은 초저지연·고효율 엣지 추론을 위해 설계됐으며, Jetson Nano 모듈을 포함한 다양한 디바이스에서 거의 지연 없이 완전한 오프라인으로 실행할 수 있습니다.
26B와 31B 모델은 고성능 추론과 개발자 중심 워크플로우에 최적화돼 에이전틱 AI에 적합합니다. 이들 모델은 활용성을 높인 최첨단 추론 성능을 제공하도록 설계됐으며, NVIDIA RTX GPU와 DGX Spark에서 효율적으로 실행돼 개발 환경, 코딩 어시스턴트, 에이전트 기반 워크플로우를 지원합니다.
로컬 에이전틱 AI가 확산됨에 따라 오픈클로(OpenClaw)와 같은 애플리케이션은 RTX PC, 워크스테이션, DGX Spark에서 항상 실행되는 AI 어시스턴트를 구현하는데요. 최신 젬마 4 모델은 오픈클로와 호환되며, 개인 파일과 애플리케이션, 워크플로우의 컨텍스트를 활용해 작업을 자동화하는 로컬 에이전트를 구축할 수 있습니다. RTX GPU와 DGX Spark에서 오픈클로를 무료로 실행하는 방법을 알아보거나 DGX Spark 오픈클로 플레이북을 통해서 확인할 수 있습니다.
구글 딥마인드(Google DeepMind) 발표 블로그에서 젬마 4 제품군의 최신 업데이트 사항을 자세히 알아보세요.
시작하기: RTX GPU와 DGX Spark에서 젬마 4
NVIDIA는 올라마(Ollama), 라마.cpp와 협력해 각 젬마 4 모델에 최적화된 로컬 배포 환경을 제공하고 있습니다.
사용자는 올라마를 다운로드해 젬마 4 모델을 로컬에서 실행하거나, 라마.cpp를 설치하고 젬마 4 GGUF 허깅페이스(Hugging Face) 체크포인트와 연동해 사용할 수 있습니다. 또한 언슬로스(Unsloth)는 최적화·양자화된 모델을 통해 언슬로스 스튜디오(Unsloth Studio)에서 효율적인 로컬 파인튜닝과 배포를 지원합니다. 지금 언슬로스 스튜디오에서 젬마 4를 실행하고 파인튜닝을 시작해 보세요.
젬마 4 제품군을 비롯한 오픈 모델을 NVIDIA GPU에서 실행하면, 최적의 성능을 구현할 수 있습니다. 바로 NVIDIA Tensor 코어가 AI 추론 워크로드를 가속해 더 높은 처리량과 낮은 레이턴시를 제공하기 때문이죠. 그리고 CUDA 소프트웨어 스택은 다양한 프레임워크와 도구 전반에 걸친 폭넓은 호환성을 보장해 신규 모델을 출시 첫날부터 효율적으로 실행할 수 있도록 지원합니다.
이러한 조합을 통해 젬마 4와 같은 오픈 모델은 엣지의 Jetson Orin Nano부터 RTX PC, 워크스테이션, DGX Spark에 이르기까지 다양한 시스템에서 별도의 대규모 최적화 없이 원활하게 실행됩니다.
NVIDIA 테크니컬 블로그에서 NVIDIA GPU에서 젬마 4를 시작하는 방법을 알아보고, 오픈 모델 관련 NVIDIA의 다양한 활동을 확인해 보세요.
#ICYMI: RTX AI PC 최신 업데이트
✨ RTX AI Garage 블로그를 통해 NVIDIA GTC에서 공개된 다양한 에이전틱 AI 관련 발표를 확인해 보세요. 로컬 에이전트를 위한 신규 오픈 모델인 NVIDIA Nemotron 3 Nano 4B와 Nemotron 3 Super 120B, 큐원 3.5(Qwen 3.5)와 미스트랄 스몰 4(Mistral Small 4)에 대한 최적화가 포함돼 있습니다.
NVIDIA는 최근 오픈클로 경험을 NVIDIA 디바이스에서 최적화하기 위해 보안을 강화하고 로컬 모델을 지원하는 오픈소스 스택인 NVIDIA NemoClaw를 공개했습니다.
🚀 어컴플리시.ai(Accomplish.ai)는 내장 모델을 포함한 오픈 소스 데스크톱 AI 에이전트의 무료 버전인 어컴플리시 프리(Accomplish FREE)를 발표했습니다. 이 에이전트는 NVIDIA GPU를 활용해 오픈 웨이트 모델을 로컬에서 실행하는데요. 동시에 하이브리드 라우터를 통해 로컬 RTX 하드웨어와 클라우드 간 워크로드를 동적으로 분산하며, 애플리케이션 프로그래밍 인터페이스 키 없이도 빠르고 안전하며 별도 설정 없이 실행할 수 있도록 지원합니다.
페이스북(Facebook), 인스타그램(Instagram), 틱톡(TikTok), X에서 NVIDIA AI PC를 확인하고, RTX AI PC 뉴스레터를 구독해 최신 소식을 받아보세요.
링크드인(LinkedIn)과 X에서 NVIDIA Workstation을 팔로우하세요.