AI 애플리케이션 제작의 주요 과제와 목표의 하나는 높은 정확도를 겸비한 고성능 모델을 제작하는 것입니다. 이러한 딥 러닝 모델의 개발에는 긴 시간이 소요됩니다. 재훈련과 미세 조정, 최적화를 거치며 필수적인 구성요소를 만족하는 모델이 되기까지 수 주일 또는 수 개월이 걸릴 수 있습니다. 사실 딥 러닝 AI 파이프라인을 처음부터 구축하는 것이 현실적으로 불가능한 개발자들의 수도 상당하죠. 바로 이것이 NVIDIA가 NGC catalog를 개발한 이유입니다.
NGC catalog는 AI와 HPC 컨테이너, 사전 훈련된 모델, SDK, 헬름 차트(Helm chart)들의 GPU 최적화 허브로 엔드 투 엔드 워크플로우의 간소화와 가속화를 위해 고안됩니다.
NGC catalog는 또한 헬스케어와 소매, 제조 등 다양한 영역을 비롯하여 컴퓨터 비전, 음성과 언어의 이해와 같은 AI 업무 전반에서 각 작업별로 사전 훈련된 모델을 호스팅합니다. 이번 포스팅에서는 NGC catalog가 제공하는 사전 훈련된 모델의 이점을 살펴보겠습니다. 이와 더불어 사전 훈련된 모델을 컴퓨터 비전에 적용하여 손동작 인식 AI 애플리케이션을 구축하는 방법을 소개하겠습니다.
사전 훈련된 모델을 활용하는 이유는?
AI 모델을 처음부터 구축하려면 대규모의 고품질 데이터세트에 접근할 수 있어야 합니다. 하지만 이러한 데이터세트의 액세스는 쉬운 일이 아니기 때문에 독자적으로 데이터를 확보하거나 타사의 리소스에 의존해야 할 수 있습니다. 일단 데이터가 확보된다고 하더라도 훈련용 데이터로의 재구성과 준비가 필요할지도 모릅니다. 결국 데이터 사이언티스트들은 AI 모델의 설계보다 데이터의 분류, 주석화(annotation), 변환에 더 긴 시간을 할애해야 하는 문제에 직면합니다.
또한 일반적인 개발 과정에는 오픈 소스 프레임워크로 딥 러닝 모델을 구축한 후 훈련, 개선, 재훈련을 수차례 거듭하며 다수의 반복(iteration)에서 소기의 정확도를 달성하는 과정이 수반됩니다. 여기에서 딥 러닝 모델의 규모와 복잡성이 또 다른 문제로 작용합니다. 지난 5년 사이 컴퓨팅 리소스에 대한 수요는 5년 전의 ResNet 50에서 현재의 BERT-Megatron 모델에 이르기까지 약 30,000배 증가했습니다. 이러한 대형 모델을 처리하려면 대규모 클러스터에 액세스하여 멀티 노드 시스템이 제공하는 확장성을 활용할 수 있어야 합니다.
사전 훈련된 모델은 그 명칭이 의미하는 바와 같이 특정 영역을 대표하는 데이터세트로 미리 훈련을 진행한 모델을 말합니다. 이 모델에는 대표 데이터세트에 맞춰 미세 조정된 가중치(weight)와 편향(bias)이 포함되어 있습니다. 개발을 가속화하고 싶으면 사전 훈련된 모델을 출발점으로 삼으면 됩니다. 시간을 절약하고 모델의 개선에 필요한 반복(iteration)의 횟수도 늘릴 수 있습니다. 여기에서 사용되는 기법이 전이 학습(Transfer Learning)입니다.
사전 훈련된 모델의 다양한 유스 케이스와 활용 영역
NVIDIA NGC catalog는 자율주행, 헬스케어, 제조, 소매 등 특정 산업에 특화된 모델들을 호스팅합니다. 다음의 유스 케이스(use case)를 위한 모델들도 함께 제공합니다.
컴퓨터 비전(Computer vision)
- 탐지(Detection): SSD PyTorch
- 분류(classification): ResNet50 v1.5, resnext101-32x4d
- 분할(segmentation): MaskRCNN, UNET Industrial
음성(Speech)
- 자동 음성 인식: Jasper
- 음성 합성: FastPitch, TacoTron2, Waveglow
- 번역: GMNT, Transformer
이해(Understanding)
- 언어 모델링: BERT, Electra
- 추천 시스템: Wide and Deep, VAE
사전 훈련된 모델은 NVIDIA Research와 NVIDIA의 파트너사들이 직접 개발합니다. 사전에 훈련을 마친 모델을 기존의 산업용 SDK에 원활히 통합할 수 있습니다. 일례로 헬스케어용 NVIDIA Clara, 대화형 AI용 NVIDIA Riva, 딥 러닝 추천 시스템용 NVIDIA Merlin, 자율주행 자동차용 NVIDIA DRIVE 등과 손쉽게 통합되어 제작의 속도를 높입니다.
모델 자격 증명
모델에 포함된 자격 증명(credential)은 사용자가 원하는 AI 소프트웨어 개발을 위해 배포해야 할 적합한 모델을 신속히 식별할 수 있게 해줍니다. 자격 증명이 제공하는 평가표에는 훈련 구성(training configurations), 성능 지표(performance metrics) 등의 핵심 파라미터들이 기록되어 있습니다. 특히 성능 지표는 모델의 정확도, 에포크(epoch), 배치(batch) 사이즈, 정밀도, 훈련 데이터세트, 처리량 등 중요한 하이퍼 파라미터들을 보여주어 모델의 유용성을 파악하고 배포에 확신을 가질 수 있게 도와주죠.
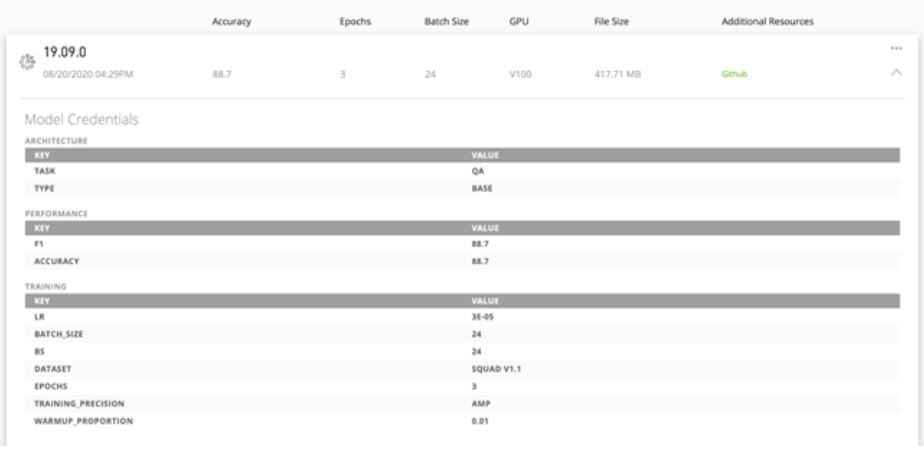
자격 증명을 활용하면 적합한 모델을 신속히 규명하고 프로덕션의 배포 속도 또한 높일 수 있습니다. 모델 평가표의 지표(metrics)는 커스터마이징이 가능하므로 적합한 속성들을 사용해 모델의 특성을 더 잘 설명할 수도 있습니다. 예를 들어 컴퓨터 비전 모델의 추론 성능을 설명하는 데는 초당 이미지(images-per-second) 지표가 더 훌륭한 반면 NLP 모델에는 초당 문장(sentences-per-second) 지표가 더 적합합니다.
전이 학습(Transfer Learning)
모델의 선택이 끝나면, 사전에 학습한 내용과는 다른 업무의 수행이 가능하도록 여러분이 지정한 데이터세트로 훈련을 진행해야 합니다. NVIDIA Transfer Learning Toolkit(TLT)는 Python 기반 AI 툴키트로 특정 목적을 위해 사전 훈련된 AI 모델을 가져와 여러분의 데이터로 커스터마이징합니다. TLT는 널리 사용되는 네트워크 아키텍처와 백본을 여러분의 데이터에 적용하여 훈련, 미세 조정, 프루닝을 진행하고 엣지단(edge deployment)의 배포에 고도로 최적화되고 정확한 AI 모델을 내보내게 해줍니다. TLT는 사전 훈련된 모델 일체에 표준 기능으로 포함되어 있습니다. 사전 훈련된 모델들을 여러분의 데이터로 미세 조정하세요. 이를 통해 모델의 개발에 소요되는 시간을 약 10배까지, 예를 들어 80주를 8주로 크게 단축할 수 있습니다.
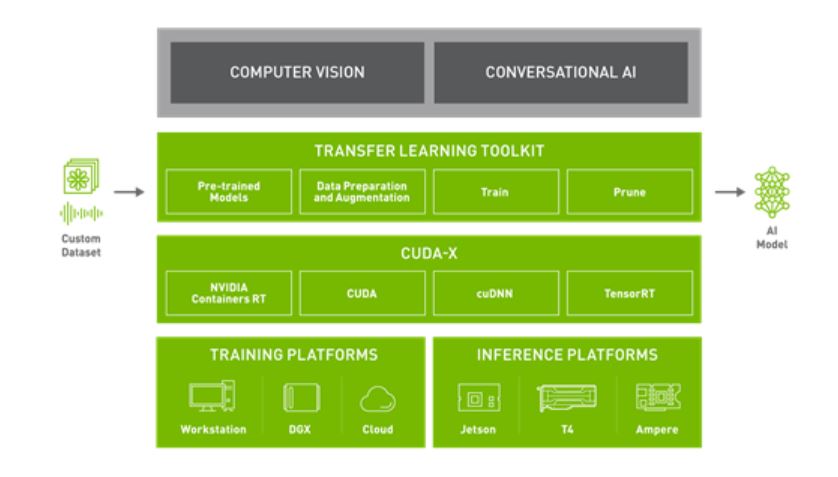
훈련 성능의 가속화
이 섹션에서는 사전 훈련된 모델을 실현하는 핵심 테크놀로지에 등장한 혁신들을 살펴보겠습니다. 바로 자동 혼합 정밀도(automatic mixed precision, AMP)와 다중 GPU 훈련입니다.
자동 혼합 정밀도
심층 신경망은 FP16과 FP32 정밀도를 사용하는 혼합 정밀도 전략으로 훈련이 가능한 경우가 많습니다. 이렇게 하면 컴퓨팅 시간과 메모리 대역폭의 요구 수준을 크게 줄이면서도 모델의 정확도를 유지할 수 있습니다. 더 자세한 내용은 NVIDIA Research 보고서 Mixed Precision Training을 참고하세요. AMP를 활용하면 코드의 변경 없이, 혹은 최소한의 변경만으로 혼합 정밀도를 구현할 수 있습니다.
AMP는 NGC의 모델 일체에 포함된 표준 기능입니다. AMP는 NVIDIA Volta, NVIDIA Turing, NVIDIA Ampere Architecture 상의 Tensor Core를 자동으로 사용합니다. Tensor Core로 훈련을 진행하면 결과의 도출이 최대 3배까지 빨라집니다.
다중 GPU 훈련
다중 GPU 훈련은 NGC 모델 일체에 구현되어 있는 표준 기능입니다. 그 기저에서의 분산 훈련과 통신 효율성을 위해서는 Horovod와 NCCL 라이브러리가 활용됩니다. 모델 대부분의 경우 동종 GPU로 구성된 세트상에서의 다중 GPU 훈련은 GPU의 개수를 설정해 진행할 수 있습니다.