
그동안 컨슈머 컴퓨팅의 패러다임은 PC에서 스마트폰, 태블릿에 이르기까지 개인용 디바이스라는 개념을 중심으로 진화해 왔습니다. 그러나 생성형 AI, 특히 오픈클로(OpenClaw)의 등장은 ‘에이전트 컴퓨터’라는 완전히 새로운 카테고리를 탄생시켰죠. 이러한 디바이스는 NVIDIA DGX Spark 데스크톱 AI 슈퍼컴퓨터나 NVIDIA RTX PC와 같이, 개인용 에이전트를 프라이버시를 유지한 채 무료로 실행하는 데 이상적입니다.
이번 NVIDIA GTC에서는 다음과 같은 혁신적인 에이전틱 AI 관련 발표들이 소개됐습니다.
- NVIDIA Nemotron 3 Nano 4B와 Nemotron 3 Super 120B를 포함한 로컬 에이전트를 위한 신규 오픈 모델이 공개됐습니다. 큐원5(Qwen 3.5)와 미스트랄 스몰 4(Mistral Small 4)에 대한 최적화도 이뤄졌습니다.
- 오픈클로를 위한 오픈 소스 스택인 NVIDIA NemoClaw는 보안성을 강화하고 로컬 모델을 지원함으로써 NVIDIA 디바이스에서의 오픈클로 사용자 경험을 극대화합니다.
- 언슬로스 스튜디오(Unsloth Studio)를 통한 파인튜닝 간소화로 에이전틱 워크플로우를 위한 오픈 모델의 정확도를 더욱 향상시킬 수 있습니다.
GTC 참가자들은 3월 19일(현지시간)까지 매일 오전 8시-오후 5시 GTC 파크(GTC Park)에서 열린 NVIDIA build-a-claw 행사에 참여했습니다. 현장에서 NVIDIA 전문가들은 참가자들이 각자의 디바이스를 활용해 상시 구동되는 능동형 AI 어시스턴트를 맞춤형으로 구축하고 배포할 수 있도록 지원했죠. 이번 행사는 기술 숙련도와 관계없이 누구나 참여할 수 있었는데요. 참가자들은 자신의 에이전트에 이름을 붙이고 성격을 정의하며 필요한 도구에 대한 접근 권한을 부여해, 평소 사용하는 메시징 앱에서 바로 사용할 수 있는 개인용 어시스턴트를 직접 제작할 수 있었습니다.
신규 오픈 모델, 로컬 에이전트에 클라우드급 품질 제공
비약적으로 확장된 콘텍스트 윈도우(context window)를 갖춘 차세대 로컬 모델은 PC에서 에이전트를 구동할 수 있는 인텔리전스를 제공합니다. 풍부한 사용자 콘텍스트와 강력한 로컬 도구의 결합은 AI PC의 새로운 가능성을 열고 있죠. 특히 128GB 통합 메모리를 갖춰 1,200억 개 이상의 파라미터를 지원하는 DGX Spark와 같은 시스템에서 이러한 잠재력이 더욱 크게 발휘됩니다.
최근 출시된 Nemotron 3 Super는 1,200억 개의 파라미터와 120억 개의 활성 파라미터를 보유한 오픈 모델입니다. 복잡한 에이전틱 AI 시스템 구동을 위해 설계됐으며, DGX Spark나 NVIDIA RTX PRO 워크스테이션에서 에이전트를 가동하는 데 최적의 성능을 발휘하죠. 특히 오픈클로 환경에서 거대 언어 모델(LLM) 성능을 측정하는 새로운 벤치마크 ‘핀치벤치(PinchBench)’에서 85.6%를 기록하며, 동급 대비 최고의 오픈 모델임을 입증했습니다.
미스트랄 스몰 4는 1,190억 개의 파라미터를 갖춘 오픈 모델로, 60억 개의 활성 파라미터를 기반으로 하며, 전체 레이어를 포함하면 80억 개 규모입니다. 이 모델은 미스트랄 플래그십 모델들의 역량을 하나로 집약했죠. 이를 통해 사용자들은 일반적인 채팅과 코딩은 물론, 에이전틱 작업에 최적화된 고효율 모델을 활용할 수 있습니다.
두 모델 모두 DGX Spark와 RTX PRO GPU에서 로컬 환경으로 구동됩니다.
보다 경량의 모델을 활용하려는 GeForce RTX 사용자들을 위해, NVIDIA Nemotron 3 오픈 모델 제품군의 최신 모델인 Nemotron 3 Nano 4B가 출시됐습니다. 이 모델은 RTX AI PC에서 로컬 기반 에이전트와 어시스턴트를 구축하기 위한 작고 강력한 출발점이 되죠. 특히 하드웨어 자원이 제한된 환경에서 구동되는 게임이나 애플리케이션에서 행동을 수행하는 대화형 페르소나(persona) 구현에 적합합니다. Nemotron 3 Nano 4B는 NVIDIA GPU 기반 시스템 전반에서 활용 가능하며, 최소한의 VRAM만으로도 높은 수준의 지시 이행 능력과 우수한 도구 활용 성능을 제공합니다.
이와 함께 NVIDIA는 알리바바(Alibaba) 큐원 3.5 모델에 대한 최적화를 발표했습니다. 이 모델은 높은 정확도(27B·9B·4B)를 입증했으며, NVIDIA GPU에서 로컬 에이전트를 구동하는 데 적합합니다. 비전과 다중 토큰 예측, 262,000 토큰에 달하는 대규모 콘텍스트 윈도우를 기본으로 지원합니다. 특히 270억 파라미터 규모의 밀집 모델은 RTX 5090 GPU와 결합될 때 더욱 뛰어난 성능을 발휘하죠.
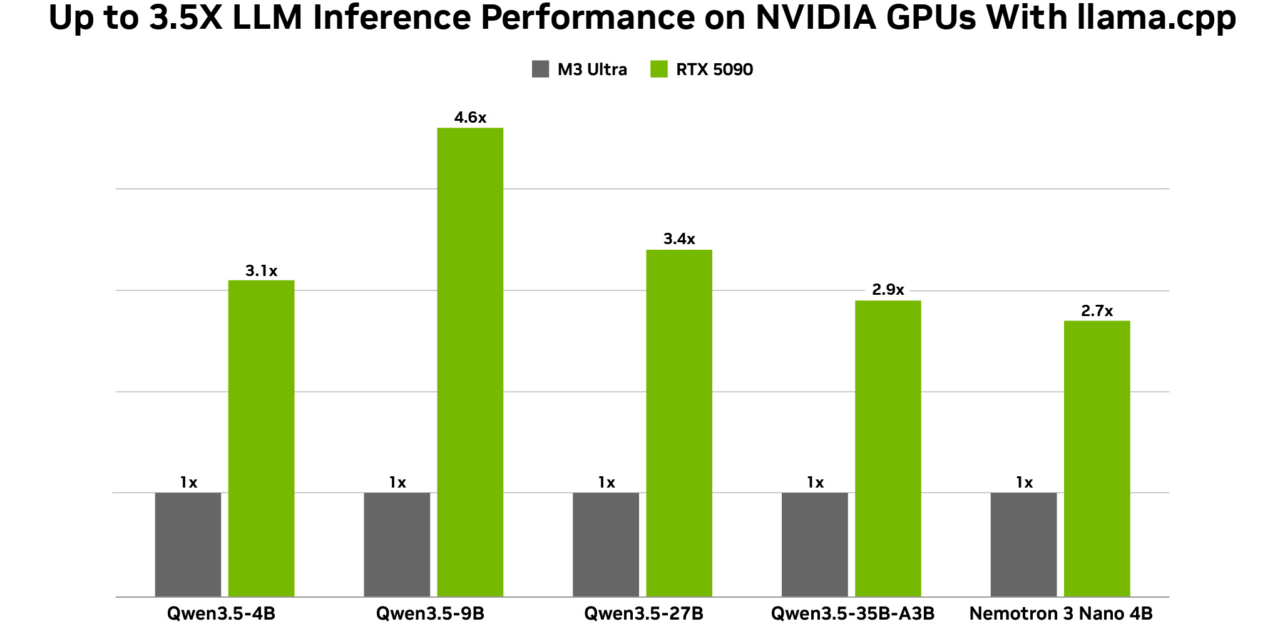
이 모델들은 올라마(Ollama), LM 스튜디오(LM Studio), 라마.cpp를 통해 활용할 수 있으며, 사용자는 RTX GPU와 DGX Spark를 기반으로 가속화된 추론을 경험할 수 있습니다. NVIDIA 오픈 모델에 대해 알아보세요.
최신 RTX 최적화 모델로 더욱 빨라진 크리에이티브 AI
이달 초 출시된 라이트릭스(Lightricks)의 최첨단 오디오-비디오 모델 LTX 2.3은 NVFP4와 FP8 증류 모델(distilled model)을 지원하며, 성능을 2.1배 향상시킵니다. 라이트릭스 LTX 2.3 모델에 대해 자세히 알아보세요.
또한 블랙 포레스트 랩스(Black Forest Labs)의 플럭스.2 클라인 9B(FLUX.2 Klein 9B) 모델은 최근 업데이트를 통해 이미지 편집 속도를 최대 2배까지 향상시켰습니다. NVIDIA는 블랙 포레스트 랩스와 협력해 RTX GPU에서 최적의 성능과 메모리 효율을 제공하는 FP8 버전을 출시했습니다.
NVIDIA NemoClaw — 오픈클로를 위한 NVIDIA 최적화 솔루션
AI 개발자와 애호가들은 DGX Spark 슈퍼컴퓨터를 구매하거나 전용 RTX PC를 구축해, 개인 파일과 앱, 워크플로우에서 콘텍스트를 가져와 일상 업무를 자동화할 수 있는 오픈클로 등 자율 AI 에이전트를 실행하고 있습니다. 그러나 오픈클로와 같은 에이전틱 시스템의 도입이 확대되면서, 토큰 비용뿐만 아니라 보안, 프라이버시에 대한 우려가 커지고 있는데요.
이러한 문제를 해결하기 위해 NVIDIA 디바이스에서 오픈클로 최적화를 구현하는 오픈 소스 스택 NemoClaw를 공개합니다. NemoClaw에서 제공되는 첫 번째 기능은 NVIDIA Nemotron 오픈 모델과 NVIDIA OpenShell 런타임입니다. Nemotron 로컬 모델을 사용하면 사용자가 추론을 로컬에서 실행할 수 있어, 프라이버시가 강화되고 토큰 비용이 발생하지 않죠. OpenShell은 클로(claw)를 보다 안전하게 실행하도록 설계된 런타임입니다.
NemoClaw에 대해 자세히 알아보고, NVIDIA 창립자 겸 CEO 젠슨 황(Jensen Huang)의 GTC 키노트와 세션을 확인해 보세요.
언슬로스 스튜디오로 파인튜닝 간소화
오픈 모델이 빠르게 발전함에 따라, 사용자 데이터와 사용 사례에 맞춰 모델을 최적화하는 파인튜닝 기술이 모델 정확도를 높이는 수단 중 하나로 주목받고 있습니다. 기존에는 파인튜닝을 수행하려면 깊은 기술적 전문성과 코딩 역량, 방대한 설정 과정이 필요했는데요. 모델 파인튜닝과 정렬 분야의 선도적 오픈 소스 라이브러리인 언슬로스는 AI 개발자와 애호가들이 파인튜닝 과정을 손쉽게 진행할 수 있도록 웹 기반 사용자 친화적 인터페이스 ‘언슬로스 스튜디오’를 출시했습니다.
500개 이상의 AI 모델을 지원하는 언슬로스 스튜디오는 훈련과 파인튜닝 과정을 획기적으로 간소화합니다. 사용자는 데이터세트를 업로드한 뒤, 그래프 기반 캔버스를 통해 고품질 합성 데이터를 생성하고 즉시 파인튜닝 작업을 시작할 수 있죠. 언슬로스 스튜디오는 양자화된 로우 랭크 어댑테이션(quantized low-rank adaptation) 또는 로우 랭크 어댑테이션(low-rank adaptation)은 물론, 전체 파인튜닝까지 지원합니다. 사용자는 모델이 파인튜닝되는 동안 작업 진행 상황을 실시간으로 모니터링하고 시각화할 수 있죠. 그 다음 원하는 프레임워크로 모델을 내보내 같은 웹 앱 안에서 곧바로 대화를 나누며 성능을 확인해 볼 수 있습니다.
언슬로스 스튜디오의 새로운 인터페이스는 맞춤형 특화 GPU 커널을 탑재해 훈련 속도를 최대 2배 높이고 VRAM 사용량을 최대 70%까지 절감하는 언슬로스 라이브러리를 기반으로 구축됐습니다. 덕분에 신규 사용자들도 NVIDIA RTX GPU와 DGX Spark의 성능을 즉시 최대로 활용할 수 있습니다.
언슬로스 스튜디오는 Nemotron 3 Nano 4B와 큐원 3.5 신규 모델을 지원하며, 현재 사용 가능합니다. RTX AI Garage 게시물에서 NVIDIA GeForce RTX GPU를 활용한 모델 파인튜닝에 대해 자세히 알아보세요.
#ICYMI: GTC 2026 소식
✨컴피UI(ComfyUI)에서 RTX Video를 활용하는 RTX AI 비디오 생성 가이드: 올해 초 CES에서 공개된 RTX AI 비디오 생성 가이드는 크리에이터와 애호가에게 텍스트 투 이미지(text-to-image) 워크플로우를 활용해 AI 생성 비디오용 키프레임(keyframe)을 제작하고, 로컬 GPU에서 RTX 비디오 기술을 사용해 4K로 업스케일링하는 방법을 안내합니다. 가이드를 따라 제작한 작품은 #AIonRTX 해시태그로 소셜 미디어에 공유해 보세요.
💿미디어를 위한 NVIDIA AI: 리눅스(Linux)와 윈도우(Windows)에서 향상된 오디오와 비디오, 증강 현실 등 NVIDIA Broadcast 수준의 AI 효과를 손쉽게 적용 가능한 고성능 소프트웨어 개발 키트(SDK)입니다. 이는 라이브 미디어, 화상 회의, 포스트 프로덕션 워크플로우에 적용할 수 있죠. 최근 업데이트에는 보다 정확한 립싱크, 다중 활성 화자 감지, RTX PRO와 GeForce RTX 40·50 시리즈 GPU에서 RTX Video Super Resolution을 통한 4K 업스케일링 속도 향상, 배경 잡음 감소, NVIDIA Studio Voice 기능의 레이턴시 절감 등이 포함됐습니다.
💻NVIDIA DLSS 5: 올가을 출시 예정인 DLSS 5는 게임 픽셀에 사실적인 조명과 재질을 더해 렌더링과 현실 간 격차를 줄이는 AI 기반 그래픽 혁신입니다.
🤖맥슨 레드시프트(Maxon Redshift) 2026.4 버전: 신규 버전은 DLSS 기반 실시간 시각화 워크플로우를 도입해, 건축 프로젝트를 실제로 걸어 다니듯 인터랙티브한 속도와 품질로 확인할 수 있습니다. 맥슨 CTO 겸 AI 책임자인 Philip Losch는 “NVIDIA DLSS 기술은 인터랙티브한 속도로 고품질 비주얼을 구현하는 핵심 요소”라고 이야기했습니다.
🪟리인큐베이트 카모(Reincubate Camo), NVIDIA TensorRT RTX EP에 윈도우 ML 추가: 카모 스트림라이트(Camo Streamlight) 앱에서 AI 오토튠(AI Autotune)을 구현해 RTX GPU에서의 성능을 크게 향상시켰습니다.
페이스북(Facebook), 인스타그램(Instagram), 틱톡(TikTok), X에서 NVIDIA AI PC에 연결하고, RTX AI PC 뉴스레터를 구독해 최신 소식을 받아보세요.
링크드인(LinkedIn)과 X에서 NVIDIA Workstation을 팔로우할 수 있습니다.
소프트웨어 제품 정보에 관한 공지를 살펴보세요.